


Transform your regulatory compliance program with our market leading platform and comprehensive global regulatory content.
Customised solutions for enterprise-class compliance
We help organisations rethink how compliance operations are managed to deliver greater operational benefits.
Find out why large global businesses trust the industry's leading SaaS platform for Automated Regulatory Intelligence.
Simplify the end-to-end cycle of managing regulatory change
CUBE's purpose-built platform meets the most demanding compliance requirements of the world's largest enterprises. Manage everything from identification of relevant regulations to actioning and implementing policies and controls with automation.
Explore RegPlatform features
Automated Regulatory Intelligence
Understand the world’s regulatory content. Standardise and map changes to your business profile and compliance frameworks with the most comprehensive automated solution.
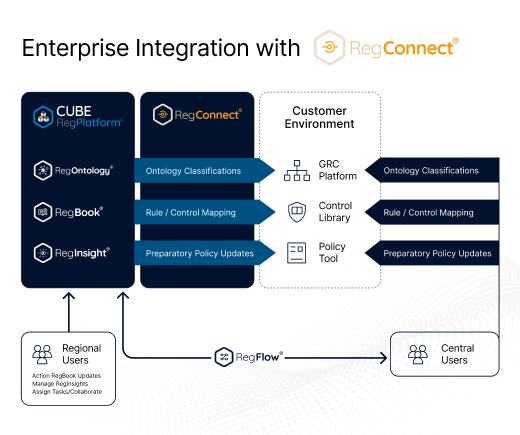
Seamlessly integrate with your existing systems
Straightforward connectivity
CUBE’s technology effortlessly integrates with third-party systems, delivering a smooth and efficient transition without disruption, loss of services or complications throughout a mission-critical process.
See more ›Get in touch
We always strive to listen and value feedback. If you have any questions, suggestions or would like to explore our Automated Regulatory Intelligence solutions, don't hesitate to get in touch. Our dedicated team is here to assist you.